Как собрать свой беспилотник за 1.5 часа¶
Что я постараюсь за сегодня рассказать:¶
- Из чего состорит автопилот
- Какие алгоритмы использует автопилот
- Какие важные части архитектуры включает в себя автопилот
- Каковыми могут быть итерации от SAE0 до SAE5
- Показать протоптанные дорожки и рассказать, как этому обучаться
- Сделать акцент на машинном обучении
- Постарать использовать лишь те технологии, которые можно использовать в домашних условиях
- Проэкспериментировать с форматом лекций
Что желательно уже знать:
- Что такое нейронные сети и как их тренируют
- Питон
Содержание¶
- Брифинг
- Курс молодого инженера
- Боевое крещение
- Разбор полетов
Глава 0. Брифинг/Подготовка¶
Язык и инструметы¶
![]()
![]()
![]()
Архитектура в общем виде¶

Control¶
Где взять модуль контроля?
Вариант 1 (с кучей денег и репутацией)
- Делаете себе имя среди компаний по производству беспилотных автомобилей
- Договариваетесь с автопроизводителем о создании совместного продукта
- Ждете выхода достаточно современного и технологически полного автомобиля, который вы сможете контролировать через некоторый интерфейс
- Готово. Теперь вы можете контролировать этот автомобиль.

Вариант 2 (с паяльником)
- Взять автомобиль с функциями круиз контроля, паркингом и т. п.
- Взломать их CAN шину, чтобы понять, как отправлять сигналы на управление скоростью.
- Купить переходничок CAN-USB в переходе.
- Готово. Теперь вы можете контролировать (частично) этот автомобиль.
см. comma.ai (NB: смотри, но лучше не пользуйся, ибо затея эта крайне авантюрная, и гост она точно не пройдет)

Вариант 3 (с кучей реле, сервоприводов и инженеров в команде)
- Взять автомобиль, проехаться на нем, посмотреть, какие педальки, ручки, колесики и кнопочки вы используете
- Собрать полностбю механизированного робота, который сможет по команде повторять ваши действия за автомобилем
- Готово.

Вариант 4 (виртуальный)
- Взять компьютерный симулятор автомобиля
- Готово.



В симуляторе можно:
- Получать ground truth
- Получать контроль миром через api (ТС, пешеходы, погодные условия)
- Генерировать, записывать и воспроизводить логи с нужными дорожными ситуациями
- Запускать сразу несколько беспилотников
- Создавать синтетические датасеты (в хороших симуляторах)
- Сиумляция разнообразных датчиков (но нам почти не понадобится)
- Реализовать обучение с подкреплением
![]()


Пара слов о OSVF
Что будем делать?¶
А давайте сначала подумаем, что такое беспилотник?

Ключевое требование - обеспечить сохранность всех участников дорожнего движения



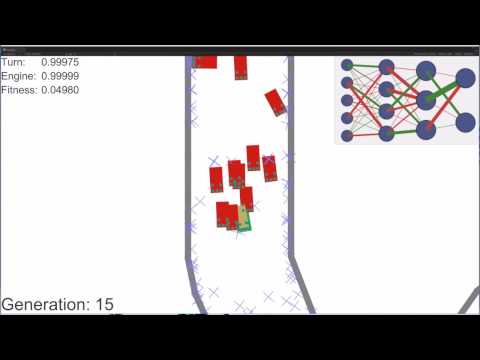
Мы начнем L1, фиксация препятствий в зоне видимости
Выбор датчиков¶
- Нам точно нужно распознавать препятствия
- Нужно распознавать проходимый путь (не пересекать сплошную и т. п.)
- Нужно распознавать объекты инфраструктуры (сигналы светофора и т. п.)
Камеры¶
Визуальный спектр¶

Как применять:
- Распознавание дорожной обстановки (светофоры, полотно, люди, машины)
- Визуальная одометрия
- Стриминг видео
- SFM
| Достоинства | Недостатки |
|---|---|
| Огромный выбор различных вариаций на рынке | Данные становятся полезными только после их обработки |
| Доступная цена | Множество параметров при выборе (разрешение, матрицы, аппаратная фунециональность) |
| Огромное количество информации, достаточной для человека | |
| Вариативность объективов | |
Стерео камеры¶


| Достоинства | Недостатки |
|---|---|
| Есть как готовые решения, так и возможности собрать самостоятельно | Вычислительная сложность |
| Большая плотность данных (зависит от разрешения и алгоритма) | Трудности с калибровкой |
| На выходе облако 3D точек и их цвет | Нелинейная ошибка |
| Возможность подстроиться под интересующую зону интересов | Необходимость грамотного подхода к выбору зоны интересов |
| Необходимость синхронизации затворов камер |
Структурированный свет¶


| Достоинства | Недостатки |
|---|---|
| Дешевое решение | Низкая дальность |
| Большая плотность точек реконструкции | |
| На выходе облако 3D точек и их цвет |
Ик (ближний, SWIR, тепловизоры)¶



Матрицы камер работают в различных ИК диапозонах (могут включать в том числе и видимый спектр)
| Достоинства | Недостатки |
|---|---|
| Работа в условиях низкой освещенности | Диапозон, предоставляющий наиболее подробную информацию о температуре, стоит очень дорого |
| Отлично подходят для распознавания людей и работающей техники | Диапозон, предоставляющий наиболее подробную информацию о температуре, накладывает расходы на установку |
ToF¶



| Достоинства | Недостатки |
|---|---|
| Небольшой размер | Низкая дальность |
| Точность | Чувствительность к фоновому свету |
| Частота до 160Гц |
Характеристики готовых решений: https://rosindustrial.org/3d-camera-survey
Лидары¶

Принцип работы заключается в лучевом лазерном сканировании
| Достоинства | Недостатки |
|---|---|
| Высокая точность облака точек | Высокая стоимость |
| Простота разработки | Более дешевые модели имеют проблемы с пороговым сигналом переотражения |
| Частота работы 10+ Гц | Ненадежность в сложных условиях эксплуатации |
Радары¶

| Достоинства | Недостатки |
|---|---|
| Точность определения дистанции | Низкая разрешающая способность |
| Получения данных о скорости объектов | Необходимость фильтрации данных, особенно в условиях эксплуатации среди множество металлических предметов |
| Доступный ценовой диапозон | |
| Надежность в сложных погодных условиях |
Мы остановимся на одной обычной камере:
- Дешево
- Достаточно для человека
- Большое количество открытых данных
Что делать с данными от сенсоров?¶
Обнаружение препятствий/обнаружение проходимого пути классическими методами компьютерного зрения¶
- Structure from motion

- Stereo Vision

Локализация и одометрия¶

- SLAM
- Найти некоторые ключевые точки
- Сохранить их в карту
- Использовать смщение относительно известных ключевых точек для определения движения
Глубокое машинное обучение¶
4 Основные задач компьютерного зрения и машинного обучения¶

- Классификация: в кадре находится шар
- Семантическая сегментация: в кадре находится шар или шары, вот их маска.
- Детекция объектов: в кадре находятся 7 шаров, вот зоны, где они располагаются.
- Объектная сегментация: В кадре находится 7 шаров, вот маски, где они располагаются
Классификация¶


Когда использовать:
- Необходимо распознать условия окружающей среды для выбора оптимальный претренированных сетей (к примеру погоду или время суток)

Детекция¶

Два наиболее популярных подхода:
- RPN
- Slide window
Когда использовать:
- Необходимо детектировать сам факт присутствия объекта (дор. знаки)
- Искомый объект всегда подходит под прямоугольную форму (можно комплексировать прямо на кадре)
- Точность комплексирования не так важна, либо с комплексированием не возникнет трудностей
- Нужен трекинг объекта


Семантическая сегментация¶

- Необходимо использовать sensor fusion с датчиками, дающими информацию о 3D пространстве
- Необходимо находить объекты большой площади на кадре
- Разделение на сущности не важно


Объектная сегментация¶

- Необходимо получать данные с высокой достоверностью
- Искомые объекты можно разделить на сущности
- Позволяют аппаратные ресурсы
- Нужен трекинг объекта

Детекция 3D¶

- Методы, работающие по одному кадру
- Методы, работающие по нескольким синхронным кадрам
- Методы, работающие с помощью оптического потока
- Методы, работающие с готовым трехмерным облаком точек
Когда применять?¶
В зависимости от входных данных, меняется и точность работы алгоритмов. Область применения - получение данных об объектах для их дальнейшего трекинга и предсказания пересечения траектории их движения с беспилотным транспортным средством
Детекция ключевых точек¶

- Обнаруживать людей
- Предсказывать их движение
Генерация изображения (аугментация ИИ)¶


- Аугменатция данных (день->ночь, зима->лето)
- Повышение реалистичности симуляторов с встроенной разметкой
Повышение разрешения¶

- Повышение разрешения карты диспаратности
- Уменьшение вычислительных ресурсов процессора
- Уменьшение объема передаваемых данных при трансляции кадров
Предсказание глубины¶

- Предсказание глубины по одному кадру для обнаружения препятствий и предсказанию расстояния до объектов
End-to-end learning¶

Применение было показано в самом начале
Planning¶
По данным от модулей распознавания предпринять дальнейшие действия на модуль контроля
Глава 2. Практика¶

import cv2 as cv # library for classic computer vision
import numpy as np # library for working with matrices in python
import matplotlib # library for visualization
import torch # library for machine learning
import torchvision # pretrained models and preprocessing operations
# import open3d as o3d # library for working with 3d point cloud
import PIL # library for working with images
import glob
import sys
import os
sys.path.append('../')
![]()
Почему PyTorch¶
- python style
- hub
- community
Мы будем использовать:
- Детекцию объектов
- Семантическую сегментацию
- Монокулярное стереозрение (оксюморон)
- Преобразование перспективы (для проекции на 2D)
Давайте посмотрим небольшой ролик, записанный в карле¶
seq_video = cv.VideoWriter('source_data.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640, 480))
import glob
img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
img_count = len(img_pathes)
for i, img in enumerate(sorted(img_pathes)):
img = cv.imread(img)
seq_video.write(img)
print('{}/{}'.format(i, img_count) , end='\r')
seq_video.release()
%%HTML
<video width="640" height="480" controls autoplay>
<source src="source_data.webm" type="video/webm">
</video>
Проверим доступность видеокарты¶
torch.cuda.is_available()
Проверим ресурсы видеокарты¶
!nvidia-smi -i 0
Найдем претренированную сеть для детекции¶
Задача: обнаруживать объекты препятствий на дороге (люди, машины, животные)
SSD¶
# ssd_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd', model_math='fp16').cuda().eval()
# ssd_utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_ssd_processing_utils')
# classes_to_labels = ssd_utils.get_coco_object_dictionary()
# %%time
# ouput = None
# ssd_video = cv.VideoWriter('ssd_example.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640, 480))
# img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
# img_count = len(img_pathes)
# for i, img in enumerate(sorted(img_pathes)):
# img = cv.imread(img)
# img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# tensor = T.ToTensor()(cv.resize(img, (300, 300)))
# tensor = tensor.unsqueeze(0)
# output = ssd_model(tensor.half().cuda())
# try:
# results_per_input = ssd_utils.decode_results(output)
# best_results_per_input = [ssd_utils.pick_best(results, 0.40) for results in results_per_input]
# for image_idx in range(len(best_results_per_input)):
# bboxes, classes, confidences = best_results_per_input[image_idx]
# for idx in range(len(bboxes)):
# left, bot, right, top = bboxes[idx]
# x, y, w, h = [val * 300 for val in [left, bot, right - left, top - bot]]
# x, y, w, h = int(x*2.13), int(y*1.6), int(w*2.13), int(h*1.6)
# img = cv.rectangle(img, (x, y), (x+w, y+h), (0, 0, 255))
# img = cv.putText(
# img, "{} {:.0f}%".format(classes_to_labels[classes[idx] - 1], confidences[idx]*100),
# (x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
# except RuntimeError:
# pass
# ssd_video.write(cv.cvtColor(img, cv.COLOR_RGB2BGR))
# print('{}/{}'.format(i, img_count) , end='\r')
# ssd_video.release()
%%HTML
<video width="640" height="480" controls autoplay>
<source src="ssd_example.webm" type="video/webm">
</video>
Faster RCNN¶
faster_rcnn = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True, min_size=300).cuda().eval()
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
%%time
ouput = None
faster_video = cv.VideoWriter('faster_rcnn_example.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640, 480))
img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
img_count = len(img_pathes)
for i, img in enumerate(sorted(img_pathes)):
img = cv.cvtColor(cv.imread(img), cv.COLOR_BGR2RGB)
tensor = T.ToTensor()(img)
tensor = tensor.unsqueeze(0)
pred = faster_rcnn(tensor.cuda())[0]
boxes = pred['boxes'].cpu().detach().numpy().astype(np.int32)
labels = pred['labels'].cpu().detach().numpy().astype(np.int32)
scores = pred['scores'].cpu().detach().numpy()
for idx in range(len(boxes)):
box, label, score = boxes[idx], labels[idx], scores[idx]
if score < 0.6:
continue
x, y, x2, y2 = box
img = cv.rectangle(img, (x, y), (x2, y2), (0, 0, 255))
img = cv.putText(
img, "{} {:.0f}%".format(COCO_INSTANCE_CATEGORY_NAMES[label], score*100),
(x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
faster_video.write(cv.cvtColor(img, cv.COLOR_RGB2BGR))
print('{}/{}'.format(i, img_count) , end='\r')
faster_video.release()
%%HTML
<video width="640" height="480" controls autoplay>
<source src="faster_rcnn_example.webm" type="video/webm">
</video>
!nvidia-smi -i 0
Semantic segmentation¶
Обнаруживать проходимый путь
- DeepLab v3 (resnet101), COCO
- FCN (resnet101), COCO
DeepLab v3 (Squeeze net), KITTI
semantic_segmentation = torch.hub.load('sid1057/self-driving-cars-utils', 'DeepSqueeze', pretrained=True).cuda().eval().half()
%%time
segm_video = cv.VideoWriter('segm.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640, 480))
img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
img_count = len(img_pathes)
for i, img in enumerate(sorted(img_pathes)):
img = cv.imread(img)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
tensor = T.ToTensor()(img)
tensor = tensor.unsqueeze(0)
output = semantic_segmentation(tensor.cuda().half()).float()
output = torch.argmax(output.squeeze(), dim=0).detach().cpu().numpy()
output = decode_cityscapes(output, mode='CityScapesClasses')
segm_video.write(cv.cvtColor(cv.addWeighted(output, 0.5, img, 0.9, 0), cv.COLOR_RGB2BGR))
print('{}/{}'.format(i, img_count) , end='\r')
segm_video.release()
%%HTML
<video width="640" height="480" controls autoplay>
<source src="segm.webm" type="video/webm">
</video>
!nvidia-smi -i 0
Предсказание глубины¶
Для особых объектов(машины, люди, животные), предсказывать расстояние и координату в пространстве задел на будущее
MonoDepth2 https://github.com/nianticlabs/monodepth2/¶
import networks
from utils import download_model_if_doesnt_exist
model_name = "mono_640x192"
download_model_if_doesnt_exist(model_name)
encoder_path = os.path.join("models", model_name, "encoder.pth")
depth_decoder_path = os.path.join("models", model_name, "depth.pth")
# LOADING PRETRAINED MODEL
encoder = networks.ResnetEncoder(18, False)
depth_decoder = networks.DepthDecoder(num_ch_enc=encoder.num_ch_enc, scales=range(4))
loaded_dict_enc = torch.load(encoder_path, map_location='cpu')
filtered_dict_enc = {k: v for k, v in loaded_dict_enc.items() if k in encoder.state_dict()}
encoder.load_state_dict(filtered_dict_enc)
loaded_dict = torch.load(depth_decoder_path, map_location='cpu')
depth_decoder.load_state_dict(loaded_dict)
encoder.cuda().eval()
depth_decoder.cuda().eval();
%%time
import PIL.Image as pil
from layers import disp_to_depth
depth_video = cv.VideoWriter('depth.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640, 480))
img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
img_count = len(img_pathes)
for i, img in enumerate(sorted(img_pathes)):
img = cv.cvtColor(cv.imread(img), cv.COLOR_BGR2RGB)
input_image = T.ToPILImage()(img)
original_width, original_height = input_image.size
feed_height = loaded_dict_enc['height']
feed_width = loaded_dict_enc['width']
input_image_resized = input_image.resize((feed_width, feed_height), pil.LANCZOS)
input_image_pytorch = T.ToTensor()(input_image_resized).unsqueeze(0)
with torch.no_grad():
features = encoder(input_image_pytorch.cuda())
outputs = depth_decoder(features)
disp = outputs[("disp", 0)].cpu()
disp_resized = torch.nn.functional.interpolate(
disp, (original_height, original_width), mode="bilinear", align_corners=False)
pred_disp, _ = disp_to_depth(disp_resized, 10, 100)
pred_disp = pred_disp.cpu()[:, 0].numpy()
pred_depth = 5.4 / pred_disp
disp_resized_np = cv.applyColorMap(
cv.normalize(pred_depth[0], None, 0, 255, cv.NORM_MINMAX).astype(np.uint8), cv.COLORMAP_RAINBOW)
depth_video.write(cv.cvtColor(cv.addWeighted(disp_resized_np, 0.5, img, 0.9, 0), cv.COLOR_RGB2BGR))
print('{}/{}'.format(i, img_count) , end='\r')
depth_video.release()
%%HTML
<video width="640" height="480" controls autoplay>
<source src="depth.webm" type="video/webm">
</video>
!nvidia-smi -i 0
Оформим все в виде функций¶
Получение глубины¶
def get_depth(img_rgb):
input_image = T.ToPILImage()(img)
original_width, original_height = input_image.size
feed_height = loaded_dict_enc['height']
feed_width = loaded_dict_enc['width']
input_image_resized = input_image.resize((feed_width, feed_height), pil.LANCZOS)
input_image_pytorch = T.ToTensor()(input_image_resized).unsqueeze(0)
with torch.no_grad():
features = encoder(input_image_pytorch.cuda())
outputs = depth_decoder(features)
disp = outputs[("disp", 0)].cpu()
disp_resized = torch.nn.functional.interpolate(
disp, (original_height, original_width), mode="bilinear", align_corners=False)
pred_disp, _ = disp_to_depth(disp_resized, 10, 256)
pred_disp = pred_disp.cpu()[:, 0].numpy()
# pred_depth = 5.4 / pred_disp
pred_depth = 1 / pred_disp
return pred_depth[0]
Сегментация дороги¶
def get_road_mask(img_rgb):
tensor = T.ToTensor()(img)
tensor = tensor.unsqueeze(0)
output = semantic_segmentation(tensor.cuda().half()).float()
output = torch.argmax(output.squeeze(), dim=0).detach().cpu().numpy()
return cv.inRange(output, 7, 7)
Детекция объектов¶
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
ROADWAY_OBSTACLES = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe'
]
def get_bboxes(img_rgb, depth=None):
mask_filled, mask_bbox, mask_dist = np.zeros_like(img_rgb), np.zeros_like(img_rgb), np.zeros_like(img_rgb)
img = img_rgb.copy()
tensor = T.ToTensor()(img)
tensor = tensor.unsqueeze(0)
pred = faster_rcnn(tensor.cuda())[0]
boxes = pred['boxes'].cpu().detach().numpy().astype(np.int32)
labels = pred['labels'].cpu().detach().numpy().astype(np.int32)
scores = pred['scores'].cpu().detach().numpy()
for idx in range(len(boxes)):
box, label, score = boxes[idx], labels[idx], scores[idx]
if score < 0.6 or not (COCO_INSTANCE_CATEGORY_NAMES[label] in ROADWAY_OBSTACLES):
continue
x, y, x2, y2 = box
mask_bbox = cv.rectangle(mask_bbox, (x, y), (x2, y2), (0, 0, 255))
mask_filled = cv.rectangle(mask_filled, (x, y), (x2, y2), (255, 0, 0), cv.FILLED)
mask_dist = cv.rectangle(mask_dist, (x, y), (x2, y2), (0, 0, 255))
mask_bbox = cv.putText(
mask_bbox, "{} {:.0f}%".format(COCO_INSTANCE_CATEGORY_NAMES[label], score*100),
(x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
if depth is not None:
dist = depth[y2-1:y2, x2-1:x2].mean().astype(np.uint8)
mask_dist = cv.putText(
mask_dist, "{}m".format(dist),
(x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
return mask_filled, mask_bbox, mask_dist
%
mask_bbox = cv.putText(
mask_bbox, "{} {:.0f}%".format(COCO_INSTANCE_CATEGORY_NAMES[label], score*100),
(x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
if depth is not None:
dist = depth[y2-1:y2, x2-1:x2].mean().astype(np.uint8)
mask_dist = cv.putText(
mask_dist, "{}m".format(dist),
(x,y), cv.FONT_HERSHEY_SIMPLEX, 0.75,(255,255,255),1,cv.LINE_AA)
return mask_filled, mask_bbox, mask_dist
Преобразование перспективы¶
IMAGE_H = 480
IMAGE_W = 640
src = np.float32([[292, 275], [353, 275], [564, 480], [55, 480]])
dst = np.float32([[IMAGE_W//8*3, IMAGE_H//2], [IMAGE_W//8*5, IMAGE_H//2], [IMAGE_W//8*5, IMAGE_H], [IMAGE_W//8*3, IMAGE_H]])
M = cv.getPerspectiveTransform(src, dst) # The transformation matrix
def get_bird_view(img_rgb):
return cv.warpPerspective(img_rgb, M, (IMAGE_W, IMAGE_H))
Объединяем все вместе¶
%%time
import PIL.Image as pil
from layers import disp_to_depth
complex_video = cv.VideoWriter('complex.webm', cv.VideoWriter_fourcc(*'VP80'), 10, (640*2, 480*2))
img_pathes = glob.glob(CARLA_dataset_path + 'leftImg8bit/*/*/*')
img_count = len(img_pathes)
for i, img in enumerate(sorted(img_pathes)):
result_image = np.zeros((480*2, 640*2, 3), dtype=np.uint8)
img = cv.imread(img)
cv.imwrite('img.png', img)
img_rgb = cv.cvtColor(img, cv.COLOR_BGR2RGB)
road_mask = get_road_mask(img_rgb)
depth = get_depth(img_rgb)
mask_filled, mask_bbox, mask_dist = get_bboxes(img_rgb, depth)
view = cv.add(img_rgb, mask_filled)
view[..., 1] = cv.addWeighted(view[..., 1], 1, road_mask, 0.3, 0)
view = get_bird_view(view)
complex_image = img_rgb.copy()
complex_image[..., 1] = cv.addWeighted(complex_image[..., 1], 1, road_mask, 0.3, 0)
complex_image = cv.add(complex_image, mask_dist)
depth_for_viz = cv.applyColorMap(
cv.normalize(depth, None, 0, 255, cv.NORM_MINMAX).astype(np.uint8), cv.COLORMAP_RAINBOW)
depth_for_viz = cv.cvtColor(depth_for_viz, cv.COLOR_BGR2RGB)
result_image[:480, :640] = img_rgb
result_image[:480, 640:] = complex_image
result_image[480:, :640] = depth_for_viz
result_image[480:, 640:] = view
complex_video.write(cv.cvtColor(result_image, cv.COLOR_RGB2BGR))
print('{}/{}'.format(i, img_count) , end='\r')
complex_video.release()
%%HTML
<video width="1280" height="720" controls autoplay>
<source src="complex.webm" type="video/webm">
</video>
!nvidia-smi -i 0
- Это в 3 раза меньше чем память у Jetson Nano за ~99$


Кто ещё делает нечто подобное?
- comma.ai
- sendtex
Что дальше?¶
Следующая игра?¶
- Не снижать скорость ниже заданного значения
- Данные берутся только с одной камеры
- Избегать столкновений, ориентируясь как на препятствия, так и на дорожную обстановку
Для этого требуется:
- Разработать программную архитектуру
- Написать скрипт контроля
- Написать модуль планирования

Out Run: За наименьшее время добраться из пункта А в пункт Б не попав в аварию

Chase HQ: Протаранить машину преступника, которая соответствует написанной сегодня нами

F1: пройти закрытый от других участников движения маршрут быстрее соперников

Colin McRae 2.0: Пройти маршрут по открытой местности быстрее соперников

NFS Most Wanted (2003): Пройти городской маршрут быстрее соперников, при условии ухода от погони
Где подвох?¶
- Хорошие условия эксплуатации
- 99.(9)%
- Аппаратная часть
- Нет необходимости комплексировать различные датчики
- Нет модуля планирования
- Модуль контроля из коробки
Спасибо за внимание!¶
- email: ivanov.dale@gmail.com (
topic: self-driving) - github: sid1057
- linkedin: ivan-deylid
Ссылка на код, презентацию, материалы и продолжение тутора: sid1057.github.io/self-driving